作者:寒歌
RPC框架的选择
常见的RPC框架主要分为轻重两种。较轻的框架一般只负责通信,如rmi、webservice、restful、Thrift、gRPC等。较重的框架一般包括完整的服务发现、负载均衡策略等等如BAT三家的Dubbo、brpc、Tars之类。
框架选择时个人认为首先要考虑的是框架的历史和项目的活跃程度。一个历史悠久的活跃项目(大概至少可以保证每两到三个月有一次小版本的更新)可以保证各种bug早已暴露并修复,让我们可以更专注于我们自己的项目本身,而不是要担心究竟是我们自己的代码有问题还是框架本身就有问题。
重量级RPC框架有一个主要问题就是结构复杂,另外主语言之外的代码质量也不太容易保证。个人认为活跃的社区以及一个活跃的开源管理团队是这些重型RPC框架项目成功的必要前提条件。比如我们项目组试用过腾讯的Tars,C++同学表示没有任何问题,然后JAVA同学表示java版本有许多bug,修复bug的pull request需要两个多月才能得到merge,而官方jar包也将近两年没有更新过了。
轻量级rpc框架中,restful可以被视作标杆。由于restful基于http协议,天然被各种框架支持,而且非常灵活。restful的缺点有两方面,一是过于灵活,缺少根据协议生成服务端和客户端代码的工具,联调往往要花更多的时间;二是大部分序列化基于json或者xml,相对来讲效率不理想。和restful相比,其它很多轻量级框架都有这样或者那样的缺点,有的缺少跨语言支持(rmi),有的既繁琐又缺乏效率优势(webservice)。个人认为其中相对理想的是gRPC和Thrift。
gRPC简介
Protobuf是一种google推出的非常流行的跨语言序列化/反序列化框架。在Protobuf2中就已经出现了用rpc定义服务的概念,但是一直缺少一种流行的rpc框架支持。当Http2推出之后,google将Http2和protobuf3结合,推出了gRPC。gRPC继承了Protobuf和Http2的优点,包括:
- 序列化反序列化性能好
- 强类型支持
- 向前/向后兼容
- 有代码生成机制,而且可以支持多语言
- 长连接、多路复用
同时gRPC还提供了简单地服务发现和负载均衡功能。虽然这并不是gRPC框架的重点,但是开发者可以非常容易的自己扩展gRPC这些功能,实现自己的策略或应用最新的相关方面技术,而不用像重型RPC框架一样受制于框架本身是否支持。
gRPC与Thrift对比
Thrift是Facebook推出的一种RPC框架,从性能上来讲远优于gRPC。但是在实际调研时发现有一个很麻烦的问题:Thrift的客户端是线程不安全的——这意味着在Spring中无法以单例形式注入到Bean中。解决方案有三种:
- 每次调用创建一个Thrift客户端。这不仅意味着额外的对象创建和垃圾回收开销,而且实际上相当于只使用了短链接,这是一个开发复杂度最低但是从性能上来讲最差的解决方案。
- 利用Pool,稍微复杂一点的解决方案,但是也非常成熟。但是问题在于一来缺少服务发现和负载均衡恐实现,需要很多额外开发;二来需要创建Pool数量*服务端数量个客户端,内存开销会比较大。
- 使用异步框架如Netty,可以成功避免创建过多的客户端,但是仍要自己实现服务发现和负载均衡,相对复杂。实际上Facebook有一个基于Netty的Thrift客户端,叫Nifty,但是快四年没更新了。。。
相比较而言gRPC就友好多了,本身有简单而且可扩展的服务发现和负载均衡功能,底层基于Netty所以线程安全,在不需要极限压榨性能的情况下是非常好的选择。当然如果需要极限压榨性能Thrift也未必够看。
gRPC入门
gRPC服务定义
gRPC中有一个特殊的关键字stream,表示可以以流式输入或输出多个protobuf对象。注意只有异步非阻塞的客户端支持以stream形式输入,同步阻塞客户端不支持以stream形式输入。
1 | syntax = "proto3"; //gRPC必须使用proto3 |
依赖和代码生成
由于protoc的gRPC插件需要自己编译,而且存在环境问题。推荐使用gradle或者maven的protobuf插件。入门示例项目使用了gradle,根目录build.gradle配置如下:
1 | plugins { |
子项目build.gradle如下:
1 | plugins{ |
我们的入门子项目名称叫做starter,配置好build.gradle之后,执行gradlew :starter:generateProto就可以在src/main/java下生成对应的文件:
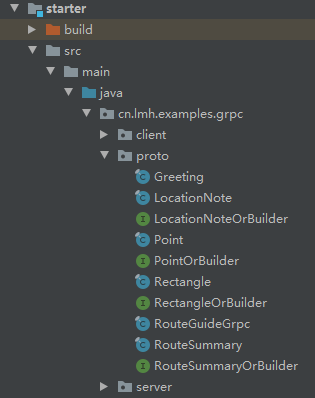
服务端
无论客户端以异步非阻塞还是同步阻塞形式调用,gRPC服务端的Response都是异步形式。对于异步的Request或者Response,都需要实现gRPC的io.grpc.stub.StreamObserver接口。io.grpc.stub.StreamObserver接口有三个方法:
onNext:表示接收/发送一个对象onError:处理异常onCompleted:表示Request或Response结束
当Request发送到服务端端时,会异步调用requestObserver的onNext方法,直到结束时调用requestObserver的onCompleted方法;服务端调用responseObserver的onNext把Response返回给客户端,直到调用responseObserver的onCompleted方法通知客户端Response结束。服务端代码如下:
1 | public class RouteGuideServer { |
客户端
gRPC的客户端有同步阻塞客户端(blockingStub)和异步非阻塞客户端(Stub)两种。同步客户端使用比较方便,但是性能较低,而且不支持stream形式的Request;异步客户端性能较高,支持stream形式的Request,但是如果想要以同步方式调用需要额外封装。本文将主要以异步为例。
异步转同步
由于gRPC的异步客户端性能较高且功能更完整,所以一般都会采用异步客户端。异步客户端接收到的Response也是以io.grpc.stub.StreamObserver形式。由于客户端的调用可能是在异步进程中但更可能是在同步进程中,所以就存在一个如何把gRPC异步Response转为同步Response的问题。
一个比较常见的思路是写一个io.grpc.stub.StreamObserver实现,里面有一个内置变量保存异步Response的结果,再添加一个阻塞式的get()方法,直到Response结束才把所有结果返回。要知道Response是否结束,需要添加一个Boolean或者AtomicBoolean变量,初始化为false,调用responseObserver.onCompleted()方法时设置为true,这样就可以通过这个变量判断Response是否结束。
阻塞get()方法最常见的思路是get()写一个while循环,直到变量值改为true才退出循环并返回结果。这种方式的优点是简单直接,任何语言都可以简单实现,缺点是由于使用循环可能CPU占用较高。而对于java这种多线程比较完善的语言,另一个比较好思路是Response结束前将线程挂起,当调用responseObserver.onCompleted()方法再唤醒线程。代码如下:
1 | public class CallableStreamObserver<T> implements StreamObserver<T> { |
客户端代码
1 | public class RouteGuideClient { |
gRPC客户端代码详解
gRPC官方将自己分为三层组件:Stub、Channel和Transport。
- Stub层是最上层的代码,gRPC附带的插件可以从.proto文件直接生成Stub层代码,开发人员通过直接调用Stub层的代码调用RPC服务
- Channel层是对Transport层功能的抽象,同时提供了很多有用的功能,比如服务发现和负载均衡。。
- Transport层承担了将字节从网络中取出和放入数据的工作,有三种实现Netty、okHttp、inProgress。Transport层是最底层的代码。
整个grpc-java项目的代码比较多。从风格上来讲,封装比较多,相对于interface更喜欢使用abstract class,相对于反射更喜欢使用硬编码,而且大量使用了单线程异步调用造成调用栈断裂,与常见的java项目的编码风格有很大差别,阅读起来可能容易不习惯。
在源码层面本文将关注下面这些方面:
- Channel的初始化过程;
- gRPC中的服务发现;
- gRPC中的负载均衡
- Client与Server之间的数据传输
Channel的初始化过程
通过入门示例可以看到,Channel的初始化过程分三步:
- 调用forTarget方法创建
io.grpc.ManagedChannelBuilder; - 配置各种选项,不论如何配置,返回的总是
io.grpc.ManagedChannelBuilder对象; - 调用build方法创建
io.grpc.ManagedChannel。
forTarget方法
gRPC这里设计比较繁琐,过程比较绕。forTarget方法的实际功能就是把参数target赋值给io.grpc.ManagedChannelBuilder的内部变量target。
1 | public static ManagedChannelBuilder<?> forTarget(String target) { |
io.grpc.ManagedChannelProvider.provider()会返回一个io.grpc.ManagedChannelProvider实现。有哪些io.grpc.ManagedChannelProvider实现是在io.grpc.ManagedChannelProvider中以硬编码形式确定的,这里其实存在利用反射改进的空间。
1 | private static final class HardcodedClasses implements Iterable<Class<?>> { |
实际上就根据依赖的jar包不同就只有两个实现,一个netty的,一个okhttp的。如果像入门示例项目一样只配置了netty实现,那就只有netty的。io.grpc.netty.NettyChannelProvider的buildForTarget方法调用的是io.grpc.netty.NettyChannelBuilder的forTarget方法。
1 | public NettyChannelBuilder builderForTarget(String target) { |
而io.grpc.netty.NettyChannelBuilder继承自io.grpc.internal.AbstractManagedChannelImplBuilder,forTarget方法实际上调用了父类的构造函数。
1 | NettyChannelBuilder(String target) { |
io.grpc.internal.AbstractManagedChannelImplBuilder的构造函数最终会是把参数赋值给target变量。
1 | protected AbstractManagedChannelImplBuilder(String target) { |
build方法
从前文可以看到,实际初始化的io.grpc.ManagedChannelBuilder实际上是io.grpc.netty.NettyChannelBuilder,其build方法实现在其父类io.grpc.internal.AbstractManagedChannelImplBuilder中。
1 | public ManagedChannel build() { |
这里的io.grpc.internal.ManagedChannelOrphanWrapper和io.grpc.internal.ManagedChannelImpl其实都是io.grpc.ManagedChannel的实现。io.grpc.internal.ManagedChannelOrphanWrapper从功能上分析没有任何作用,io.grpc.internal.ManagedChannelOrphanWrapper会为io.grpc.ManagedChannel创建弱引用,并被放置到ReferenceQueue中。如果Channel是单例的,那么意义不大;如果客户端被重复创建却没有被关闭,那么ReferenceQueue中会留下相应的引用记录,可能有助于排查问题。
io.grpc.internal.ManagedChannelImpl构造方法的几个参数中,除了第一个参数是builder本身,第二个参数是用来创建Transport的Factory,第三个参数是后台连接重试策略,第四个参数是gRPC的全局线程池,第五个和第七个都是和时间相关的对象,主要用于日志中,第六个是客户端调用时的interceptor。在io.grpc.netty.NettyChannelBuilder中,buildTransportFactory方法会创建一个io.grpc.netty.NettyChannelBuilder.NettyTransportFactory。
服务发现
前文的入门示例中直接写了target,只能连接单个Server。如果有多个可以提供服务的Server,那么就需要有一种方式通过单个target发现这些Server。在io.grpc.ManagedChannelBuilder中有一个nameResolverFactory方法,可以用来指定如何解析target地址,发现多个服务端。
nameResolverFactory方法
这个方法的实现也在io.grpc.internal.AbstractManagedChannelImplBuilder中,如果用户有自己的io.grpc.NameResolver.Factory实现的话可以通过nameResolverFactory方法指定,gRPC就会使用用户自己的io.grpc.NameResolver.Factroy实现代替gRPC自己的默认实现,否则会使用io.grpc.NameResolverRegistry中的默认实现。
io.grpc.NameResolverRegistry会通过硬编码加载io.grpc.NameResolverProvider实现,并创建一个与之有关的io.grpc.NameResolver.Factory的实现。目前硬编码加载的io.grpc.NameResolverProvider实现只有io.grpc.internal.DnsNameResolverProvider一种。
1 | private final NameResolver.Factory factory = new NameResolverFactory(); |
getDefaultSchema会匹配target中的schema(如dns),如果匹配的上,就使用相应的NameResolver.Factory,返回NameResolver决定真正的服务访问地址。
io.grpc.NameResolver
我们来看io.grpc.NameResolver
1 | public abstract class NameResolver { |
在客户端首次连接服务端的时候会调用Listener2的start方法,需要更新的时候会调用refresh方法。当Listener2接收到服务端地址时,会调用onResult方法。
io.grpc.internal.DnsNameResolver
由于gRPC支持长连接,所以如果直连的话只会访问一个域名下的一台服务器,即首次连接时通过DNS返回IP地址。io.grpc.internal.DnsNameResolverProvider是对io.grpc.internal.DnsNameResolver的简单封装,只支持以dns:///开头的地址。io.grpc.internal.DnsNameResolver会根据target获取该host下所有关联的IP,即通过DNS解析出所有的服务端IP地址。
1 | public final class DnsNameResolverProvider extends NameResolverProvider { |
可以看到io.grpc.internal.DnsNameResolver中的start和refresh方法都调用的是resolve方法,而resolve方法是执行了一个继承自Runnable的Resolve接口。
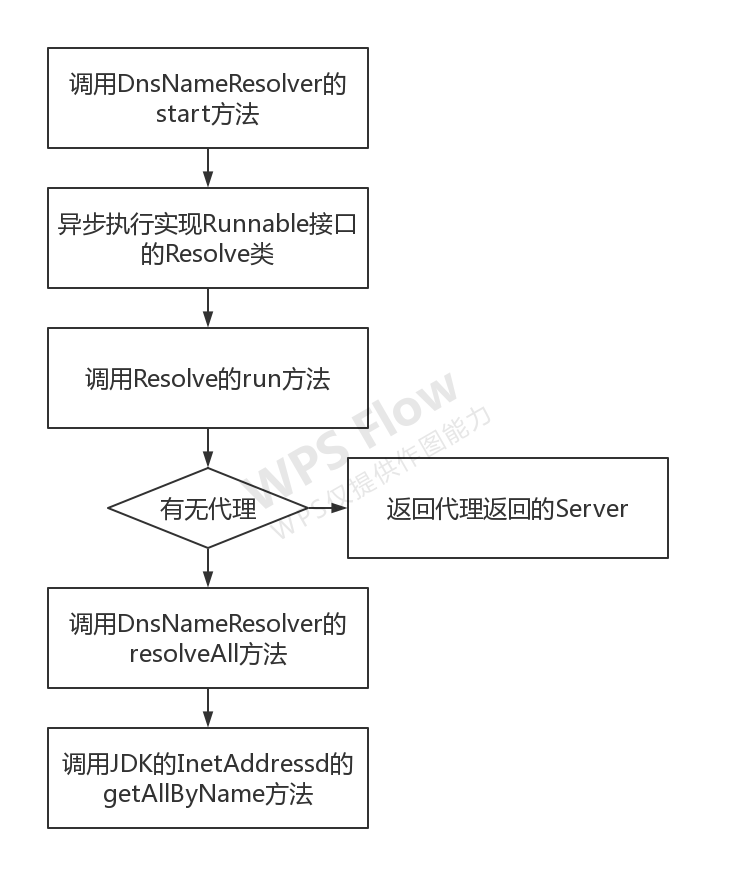
在有代理的情况下,Resolve的resolveInternal会根据代理返回的ProxiedSocketAddress创建EquivalentAddressGroup作为服务端列表返回,并设置空config;否则会调用resolveAll方法获取服务端列表,并调用parseServiceConfig方法设置config。resolveAll方法返回的ResolutionResults有三个变量addresses、txtRecords和balancerAddresses。
1 | @VisibleForTesting |
addressResolver的resolveAddress方法实际是调用JDK的java.net.InetAddress的getAllByName方法,即根据host通过DNS返回一系列服务端列表。resourceResolver根据LDAP协议获取指定命名空间下的服务端列表地址。txtRecords和balancerAddresses是和LDAP相关的参数,方法入参requestSrvRecords和requestTxtRecords的默认值都是false。由于LDAP不是特别常用,这里就不深入展开了。
NameResolverListener的onResult
当NameResolverListener获取解析结果后会调用onResult方法,进而会调用io.grpc.LoadBalancer的handleResolvedAddresses方法。

负载均衡
io.grpc.ManagedChannel初始化的时候可以通过defaultLoadBalancingPolicy方法指定负载均衡策略,实际是根据defaultLoadBalancingPolicy创建了一个io.grpc.internal.AutoConfiguredLoadBalancerFactory对象。io.grpc.internal.AutoConfiguredLoadBalancerFactory则通过io.grpc.LoadBalancerRegistry获取对应名称的负载均衡策略。io.grpc.LoadBalancerProvider的getPolicyName方法指定负载均衡策略名称,newLoadBalancer返回负载均衡io.grpc.LoadBalancer的具体实现。如果想要添加自定义负载均衡策略,需要调用io.grpc.LoadBalancerRegistry的registry方法,并自己实现io.grpc.LoadBalancerProvider和io.grpc.LoadBalancer,并指定负载均衡策略名称即可。
io.grpc.LoadBalancer.SubchannelPicker
io.grpc.LoadBalancer的核心逻辑实际在SubchannelPicker中。pickSubchannel方法会返回的PickResult中包含真正可用的subchannel,用来进行后续的数据传输。
1 | public abstract static class SubchannelPicker { |
gRPC默认提供了两种负载均衡实现策略:prick_first和round_robin。前者总会使用第一个可用的服务端,后者则是简单轮询。
handleResolvedAddresses
当服务端列表更新时,会调用io.grpc.LoadBalancer的handleResolvedAddresses方法更新可用的subchannel。
1 | @Override |
如果是首次调用(subchannel == null) 会创建subchannel,其实现是io.grpc.internal.ManagedChannelImpl.SubchannelImpl,创建的过程中会创建io.grpc.internal.InternalSubchannel。然后调用io.grpc.internal.ManagedChannelImpl的updateBalancingState方法,把subchannelPicker更新为实现Picker,然后开启subchannel的连接。
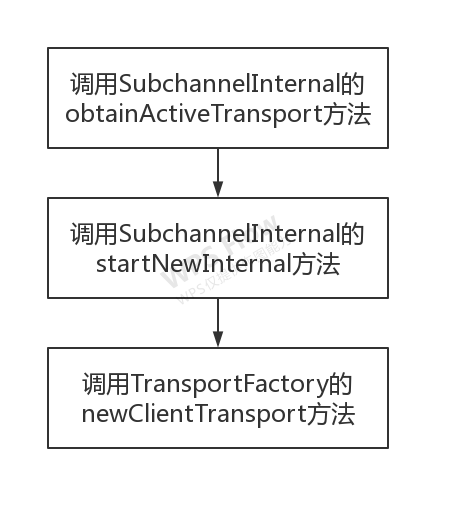
在开启subchannel的连接过程中,会调用io.grpc.internal.InternalSubchannel的obtainActiveTransport方法。
这里的transportFactory就是上面提到io.grpc.ManagedChannelBuilder调用build初始化时调用buildTransportFactory方法返回的,依赖于Transport层的具体实现。在netty实现中,返回的是io.grpc.netty.NettyClientTransport。
传输
gRPC客户端发起Request时,stub会调用ClientCalls的startCall方法,最终会调用io.grpc.internal.ManagedChannelImpl.ChannelTransportProvider的get方法获取io.grc.internal.ClientTransport。
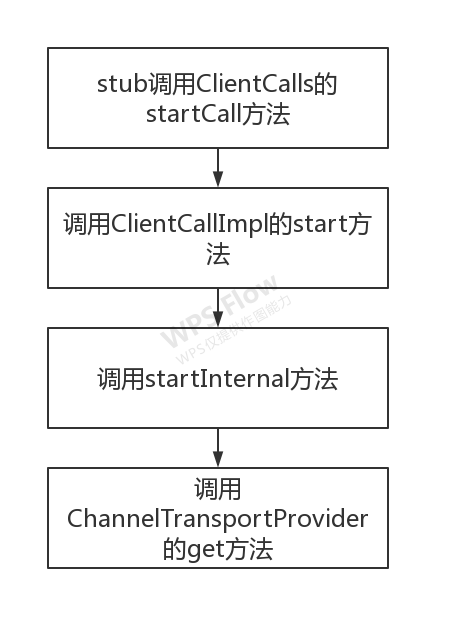
1 | public ClientTransport get(PickSubchannelArgs args) { |
如果subchannelPicker存在,会使用subchannelPicker进行选择;如果是首次访问服务端时subchannel肯定不存在,会使用syncContext异步执行exitIdleMode方法初始化。syncContext是一个单线程执行队列,可以保证先提交的任务先执行。delayedTransport的执行也依赖于syncContext,这就保证了delayedTransport中的方法执行一定会在exitIdleMode方法之后。
首次访问服务端时执行exidIdleMode方法
exitIdleMode方法会初始化NameResolver和LoadBalancer,并会启动NameResolverListener。当解析完成后会调用NameResolverListener的onResult方法,进而调用LoadBalancer的handleResolvedAddresses方法创建subchannelPicker、创建并连接subchannel。
1 | @VisibleForTesting |
Request
发送Request时会调用ConnectionClientTransport的newStream方法返回一个io.grpc.internal.ClientStream对象,而首次调用会通过delayedTransport延迟调用newStream方法。
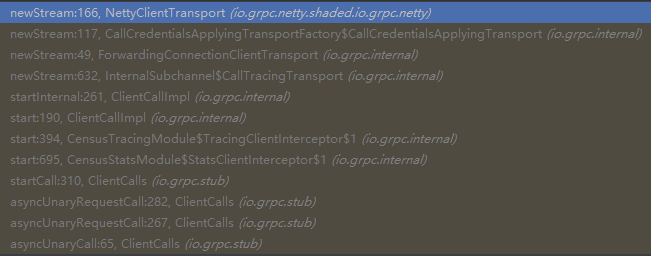
netty实现会返回一个io.grpc.netty.shaded.io.grpc.netty.NettyClientStream对象。io.grpc.internal.ClientStream下有两个子类,TransportState负责处理传输状态,Sink负责写入数据。
在进行一系列http2相关设置后,会调用io.grpc.internal.ClientStream的start方法,为TransportState设置监听并通过Sink写入Header。
1 | @Override |
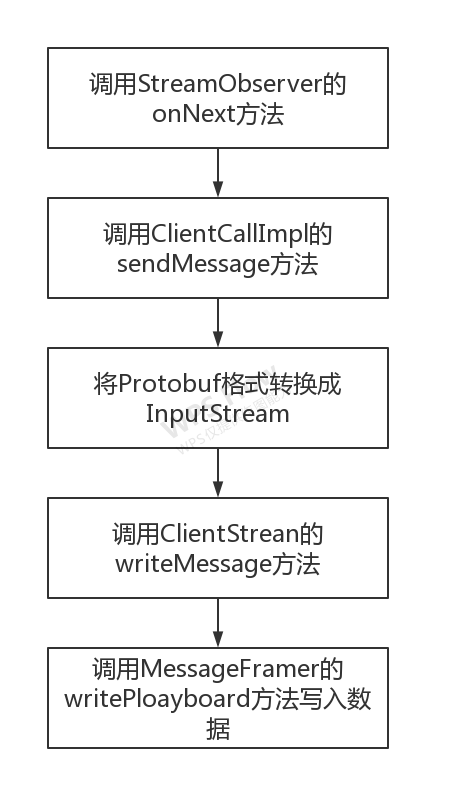
初始化结束后,调用requestObserver的onNext方法会调用io.grpc.internal.ClientCallImpl的sendMessage方法,将protobuf对象转换成InputStream,并作为参数调用io.grpc.internal.ClientStream的writeMessage方法,进而调用io.grpc.internal.MessageFramer的writePayload方法,最终调用writeToOutputStream方法将内容写入Http的OutputStream。如果是参数是stream形式会继续调用flush。
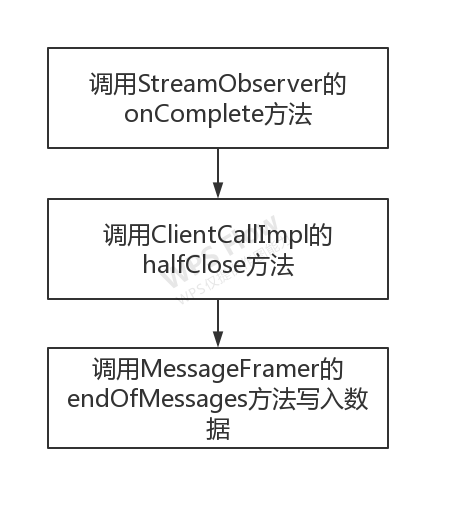
调用requestObserver的onCompleted方法会调用io.grpc.internal.ClientCallImpl的halfClose方法,进而会调用io.grpc.internal.MessageFramer的endOfMessages,flush并结束发送消息。
Response

客户端接受到Response会调用ClientStreamListener的messagesAvailable方法,并通过同步线程池最终调用StreamObserver的onNext方法接收数据。
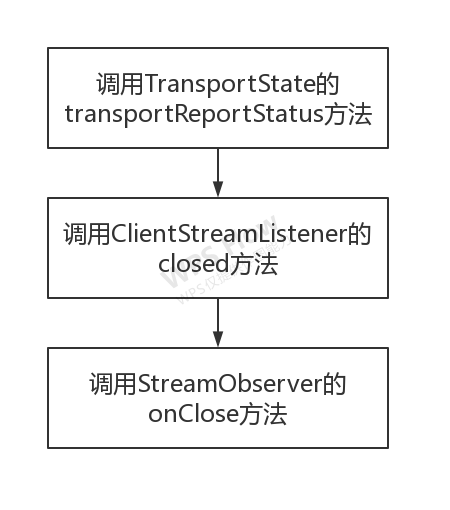
当返回结束时会调用TransportState的transportReportStatus方法关闭请求,进而调用ClientStreamListener的closed方法关闭监听,进而调用StreamObserver的onClose方法。
gRPC通信格式
gRPC发送的请求发送方法是POST,路径是/${serviceName}/${methodName},content-type为content-type = application/grpc+proto。
Request
1 | HEADERS (flags = END_HEADERS) |
Response
1 | HEADERS (flags = END_HEADERS) |
扩展gRPC
自定义基于zookeeper的NameResolver.Factory实现
1 | public class CuratorNameResolver extends NameResolver { |
自定义随机负载均衡实现
1 | public class RandomLoadBalancer extends LoadBalancer{ |
服务端初始化
服务端需要把自己的服务地址注册到zookeeper。
1 | private final int port; |
客户端初始化
客户端需要注册自定义的NameResolverFactory和LoadBalancer。
1 | public GreetingClient(String host, int port, String path) { |